With close to 39,000 results, the 2013 Chicago Marathon Results combine two of my favourite topics, statistics and running. I decided to take this opportunity to learn more about pandas by using it to analyze the result set to provide some insight into how people run marathons. (I myself ran this race)
The result of my work is in a GitHub repo and published as an IPython Notebook. I’ve extracted some of the more interesting parts.
Mundane numbers
- 55% female, 45% male
- Age group with most runners: Female, 25-29
- Average finishing time: 4:32:24.7
- Median finishing time: 4:27:26.0
- Finishing Time Percentiles:
Top 1%: 2:50:20
Top 5%: 3:14:11
Top 10%: 3:28:35
Top 20%: 3:46:58 - % of runners who met the new Chicago qualifying standards (3:15 men, 3:45 women)
women: 9.6%
men: 8.4%
Interesting Graphs
Histograms are fun because they show distributions:
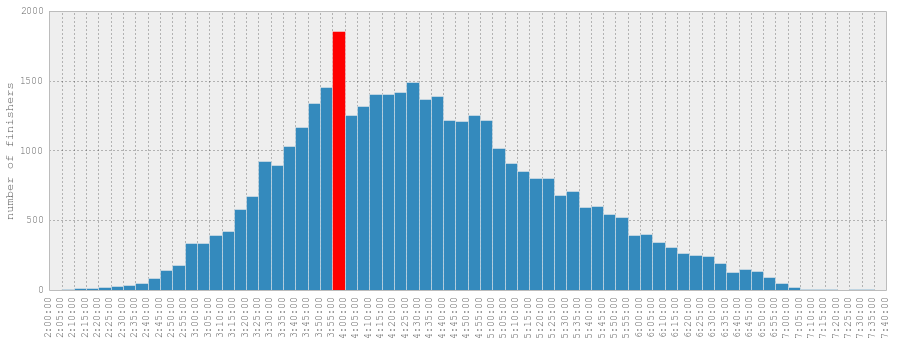
This shows the largest five-minute bin is 3:55-4:00. It’s larger by quite a bit and one possible explanation is that the most common goal time a sub-4 hour finish. This significantly skews the distribution from what you would expect if everyone ran to the limit of their ability.
Next, we have essentially the cumulative distribution function of the above: What percentage of people ran faster than a given time. The 50% point is defined as the median, which is 04:27:26.
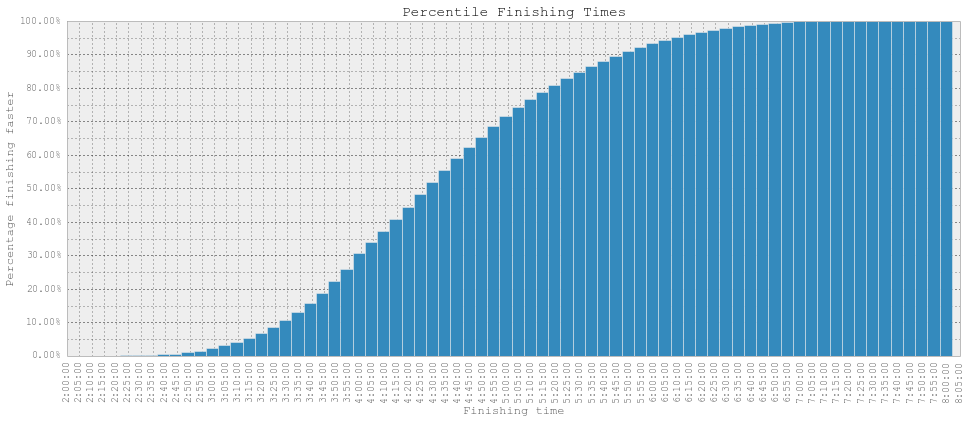
A CDF like this is a good way to compare your time with others. For example, a sub-3:30 would get you roughly into the top-10%.
Lastly, a comparison of the difference between mean male and female finish times across the different age groups:
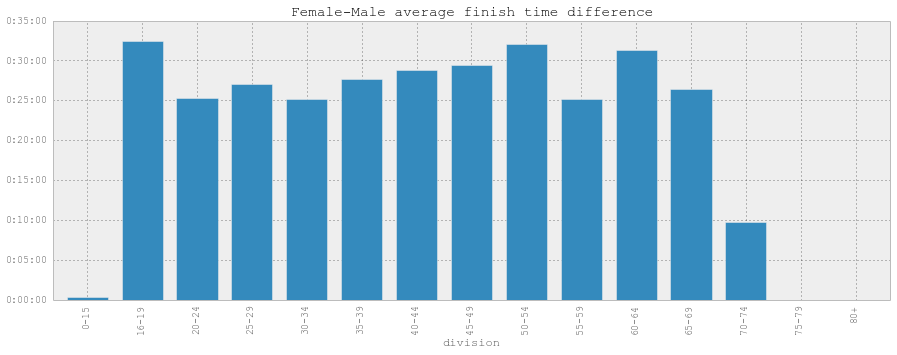
As you can see, it’s remarkable consistent, with most between 25-30 mins.
Conclusion
I’ve cherry picked which graphs to include. Check out the full analysis/IPython Notebook for more. (The analysis itself is a cherry picking of sorts)
This was a great way for me to learn the basics of the great pandas library for data analysis. I’ll be following this up with some tips on pandas learned during my brief time with it.